OSSの再利用とライセンス
近年の大規模なソフトウェア開発では,開発コスト削減のために,OSSを再利用することが一般的になりつつあります. OSSは,ソースファイルに記述されているOSSライセンスを遵守することで,ソフトウェアの一部として再利用することができます.
現在,69種類のOSSライセンスがOpen Source Initiative (OSI)に承認されています.OSSライセンスを遵守するには,まず,各ソースファイルのライセンス記述を読み,どのOSSライセンスに該当するかを特定する必要があります.

OSSライセンス特定ツールとその課題
OSSには,大量のソースファイルが含まれています.そのため,全てのソースファイルのOSSライセンスを手作業で特定するのは,現実的ではありません.そこで,手作業によるOSSライセンス特定を支援するため,ソースファイルのライセンスを自動で特定するライセンス特定ツール[1]が提案されています.
主なライセンス特定ツールは,正規表現に置き換えられた既知のライセンス記述(ライセンスルール)と,入力されたソースファイルのライセンス記述とのマッチングを行い,マッチしたライセンスルールに対応するライセンス名を出力します.

一方で,マッチするライセンスルールが存在しなかった場合,未知ライセンスであることが出力されます.
未知ライセンスが検出された場合,新しくライセンスルールを作成し,そのライセンスを特定できるようにしておくことが望ましいです.そうしないと,未知ライセンスが検出されるたびに,未知ライセンスそのものを手作業で確認しなければなりません.
しかし,多くの未知ライセンスが検出された場合,それらからライセンスルールを作成するのは容易ではありません.ライセンスルールを作成するには,まず,検出された全ての未知ライセンスを手作業で特定する必要があります.また,同一のライセンスに存在する表記ゆれを確認しなければなりません.
本研究の目的とアプローチ
本研究は,検出された未知ライセンスから,自動的に,ライセンスルールを作成することを目指しています.
その手法は,大きく分けて4つのステップから成ります.
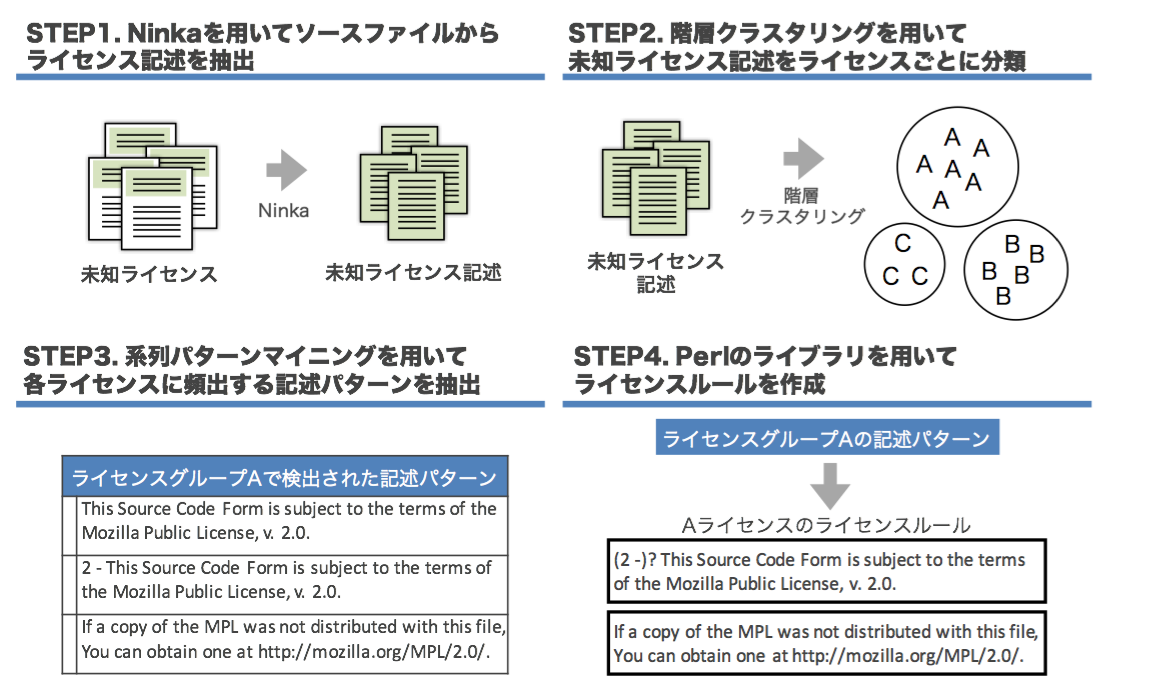
まず,前処理として,ソースファイルからライセンス記述を抽出します.次に,階層クラスタリングを用いて,検出された未知ライセンス記述をライセンスごと分類します[2].次に,系列パターンマイニングを適用し,各ライセンスに頻出する記述パターンを抽出します.最後に,Perlの正規表現作成ライブラリを用いて,頻出する記述パターンから,そのライセンスを特定するための正規表現に変換します.
[1] German, D. M., Manabe, Y. and Inoue, K.: A sentence- matching method for automatic license identification of source code files, Proc. of ASE ’10, pp. 437–446 (2010).
[2] Yunosuke, H., Manabe, Y. and Masao, O., Clustering OSS License Statements Toward Automatic Generation of License Rules, Proc. of IWESEP ’16, pp. 30–35 (2016).